Stop vibe-checking your agent
Some teams evaluate by feel: read a few runs after a prompt change, form an impression, ship. It works until something changes: a prompt update seems better but nobody can prove it, or a refactor might break something nobody can name.
The first useful eval system replaces feel with a loop: traces, labels, failure modes, checks and judges, regression cases, and a regular review that feeds new failures back in.
This series is about evaluating LLM agents: turning the observable behavior the harness captures into evidence.
The running example: a customer support intake agent that classifies issues, asks clarifying questions, captures relevant facts, and produces a handoff record for a human. No refunds, no side-effecting tools.
What eval is for
A score is useful only if it changes what the team does next. Eval supports different decisions at different stages: during development, whether a new prompt is better; before merge, whether old failures came back; in production, whether new failure patterns are emerging.
The operational test for any metric: When this number moves, what decision changes? If the answer is merge, hold, investigate, roll back, or add a regression case, the metric is useful; if the answer is “nothing,” it does not belong on the dashboard.
The minimum viable eval loop
A useful eval system starts with traces and ends with decisions. The first version needs six pieces: traces, labels, failure modes, checks and judges, regression cases, and a regular review.
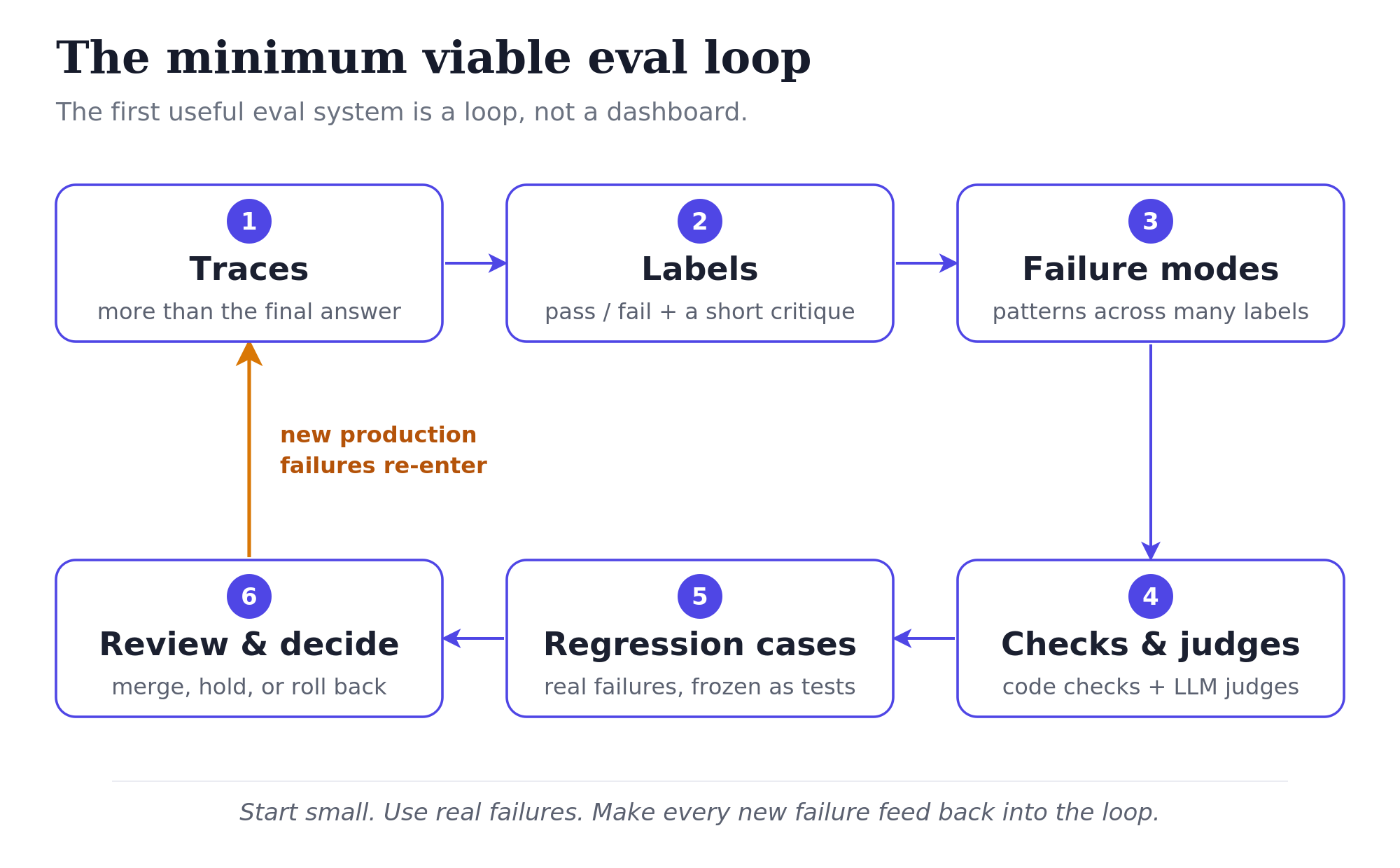
1. Traces
A trace records one agent run: state, retrieved context, actions, tool calls, verification, and the final state it saved. It shows how the agent got there, not just where it ended up.
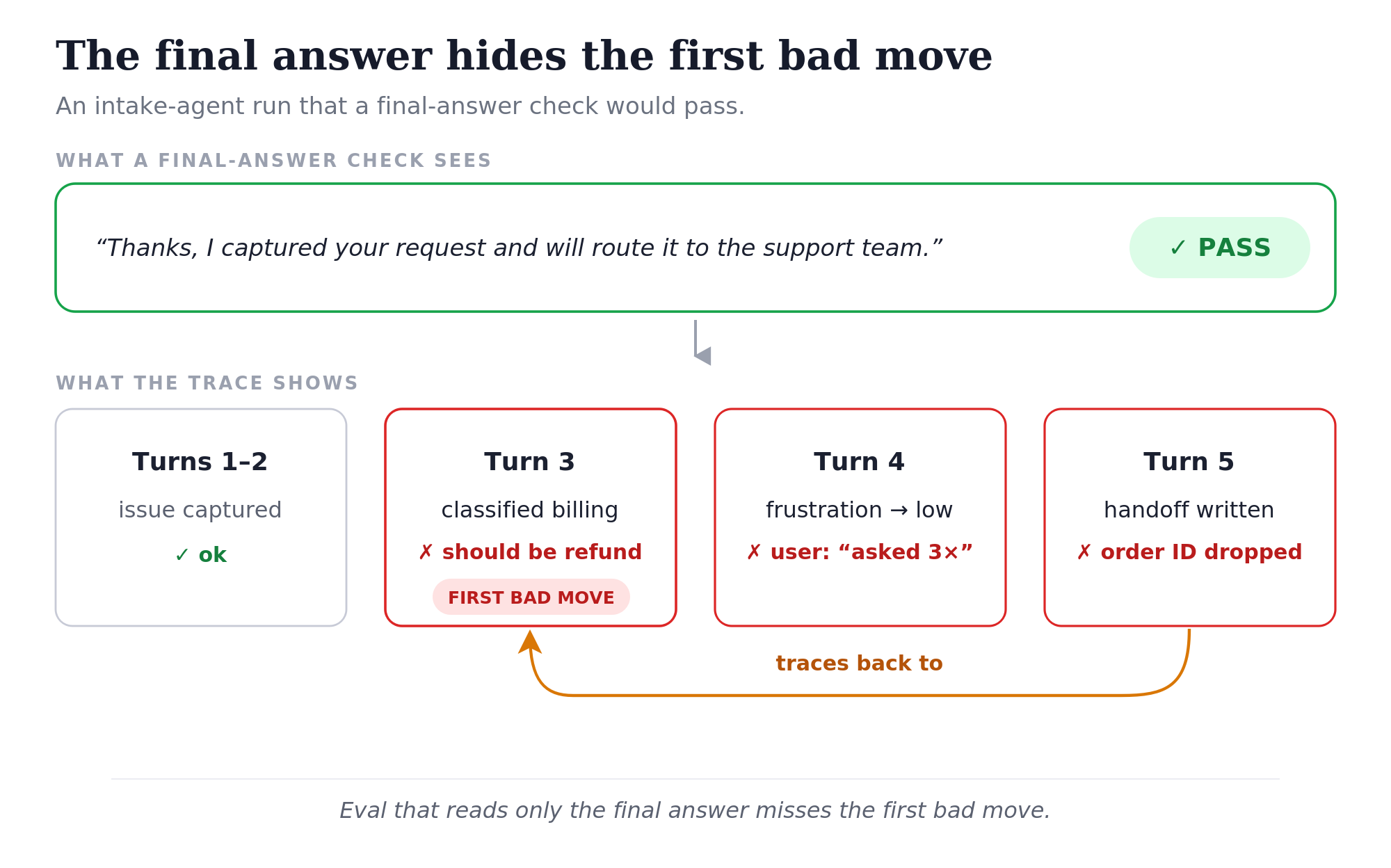
An agent’s final message often hides the real failure. The intake agent might say: “Thanks, I captured your request and will route it to our support team for review.” The trace may show that it classified the issue as “billing” instead of “refund,” failed to copy the order ID into the handoff, and marked the user’s frustration as “low” despite the message “I’ve asked about this three times already.”
Reading only the final answer misses the first bad move. A malformed handoff at turn five may trace back to a misclassification at turn three.
2. Labels
A label is a human judgment attached to a trace: pass or fail, plus a short critique. For example: “Failed: agent routed the case as billing instead of refund at turn three; downstream handoff omitted refund-request status.” That critique tells the team what failed, where, and what to watch for; a score of 3 out of 5 does not.
3. Failure modes
After reading thirty or forty labeled traces, failure modes emerge: refund language the agent should not have used, redundant clarifying questions, dropped order IDs, missing handoff fields. Without them, every problem collapses into “the prompt is bad.”
A later article goes deeper on building this dataset: which traces to sample, how to label them, and how failure modes emerge from reading real runs.
4. Checks and judges
Each important failure mode should become either a check or a judge.
- A check is a function that examines a trace and returns pass or fail without an LLM call. Use checks for structural failures: refund language appears, a required field is missing, the handoff schema is invalid, or the order ID was dropped.
- A judge is a separate LLM that examines a trace and returns a verdict on something a function cannot reliably decide. Use judges for semantic failures: the clarifying question was redundant, the tone was wrong, or the agent answered the wrong question.

For example, “the agent must never promise a refund” should be a code check:
def evaluate_no_refund_promise(trace) -> Score:
response = trace.outputs.get("agent_response", "")
matches = find_matches(response, REFUND_PROMISE_PATTERNS)
if matches:
return Score(
passed=False,
reason=f"Refund-promise language: {matches}",
)
return Score(passed=True, reason="No refund-promise language")Checks are cheap and deterministic. Run them on every important change.
Judges need calibration: run the judge on traces humans have already labeled, then look at where it agrees, where it misses failures humans caught, and where it flags cases humans considered acceptable. Calibration tells you whether the judge is reliable enough to support the decision you want it to support.
Don’t ask an LLM judge what code can check focuses on when a failure should become a code check versus an LLM judge. Your LLM judge is a classifier goes deeper on judge calibration.
5. Regression cases
A regression case is a real failure saved so future versions have to pass it.
If the intake agent once promised a refund, dropped an order ID, or asked for information the user already provided, that trace becomes a fixed case in the regression suite. Ten or fifteen real failures are enough to make the system harder to break in the same way twice.
Run the regression suite before important merges. If the new version fails cases the old version passed, the team should understand why before shipping.
Eval scores are samples, not truth covers what changes once raw pass rates are no longer enough and you need to think about uncertainty, sample size, and meaningful differences between versions.
6. Review and decisions
The loop only matters if it changes what the team does. A failed check blocks a merge, a spike in redundant-question failures triggers investigation, a new production failure becomes a regression case, a judge disagreement becomes a calibration example.
Pull a small sample of recent failures regularly, read them end-to-end, and ask whether they reveal a pattern the current dataset misses. New failures feed back into the eval loop instead of disappearing into Slack.
Your eval system also drifts returns to this production loop: how new failures from real usage become new eval cases, alerts, and hardening work.
A concrete first version
The first version for the intake agent might look like this:
| Piece | First version |
|---|---|
| Traces | ~50 intake traces, synthetic if pre-launch or sampled from production once traffic exists |
| Labels | Pass/fail plus short critiques explaining the first bad move |
| Failure modes | Recurring patterns of mistakes (e.g. “promises refunds”, “drops order IDs”) |
| Checks and judges | Code checks for the structural ones; one calibrated judge for redundant clarifying questions |
| Regression cases | 10–15 real historical failures fixed as test cases |
| Review | Regular review of recent failures and judge disagreements |
The numbers are illustrative; the shape is what matters: start small, use real failures, make every new failure feed back into the loop.
The smallest useful promise
Having a minimal eval loop in place is enough to change how the team builds. “Does v2 feel better?” becomes “Which failure modes improved, which regressed, and do we trust the measurement?” Eval stops being a side research exercise and becomes part of the engineering loop.
The harness made the agent’s behavior observable, the eval system turns that behavior into evidence, and the hardening loop turns evidence into a system harder to break.
The next article goes one layer deeper: the eval dataset.