Read traces before you write the labeling guide
The eval loop from Stop vibe-checking your agent is only as honest as the dataset underneath it. A dataset’s first job is to discover how the system fails.
The running example continues from the harness series: a scheduling assistant that books, reschedules, and cancels meetings. A user writes: “Move my meeting with Alex to next Thursday afternoon if he has time.” That one sentence assumes the assistant can guess which Alex, parse “next Thursday afternoon,” pick the right calendar, and not say “Done” before the write actually succeeds.
Start with traces, not imagined categories
A common mistake is to start with abstract qualities like accurate, helpful, concise, safe, professional. They describe how the team imagines quality before seeing how the system actually fails.
For a scheduling assistant, the real failures are more specific: choosing the wrong Alex, writing to the wrong calendar, confirming before the calendar API succeeds, losing information from earlier turns, or mishandling a forwarded email thread. These failures are concrete enough to test and fix, and they only emerge when humans read real traces.
So start with traces: label what happened, write short critiques, and let the failure modes emerge from the examples. When labeling reveals an obvious bug, fix it instead of building a judge to detect it.
Keep labels consistent
Reviewers will disagree on edge cases. Designate one adjudicator to own the labeling guide, make the call on contested cases, and update examples as the standard becomes clearer.
For domain-heavy products, the adjudicator should be whoever is closest to the product’s real standard of correctness, not whoever happens to be available. In a healthcare project I led, anchoring medical-billing-level labels to a domain expert’s judgment rather than engineers’ guesses gave the dataset real ground truth.
Keep the labels themselves simple: pass or fail. Likert scales feel more nuanced but are harder to act on and invite false precision. The nuance lives in the critique.
Design for coverage and difficulty
Once labels are consistent, the next question is whether the dataset is representative.
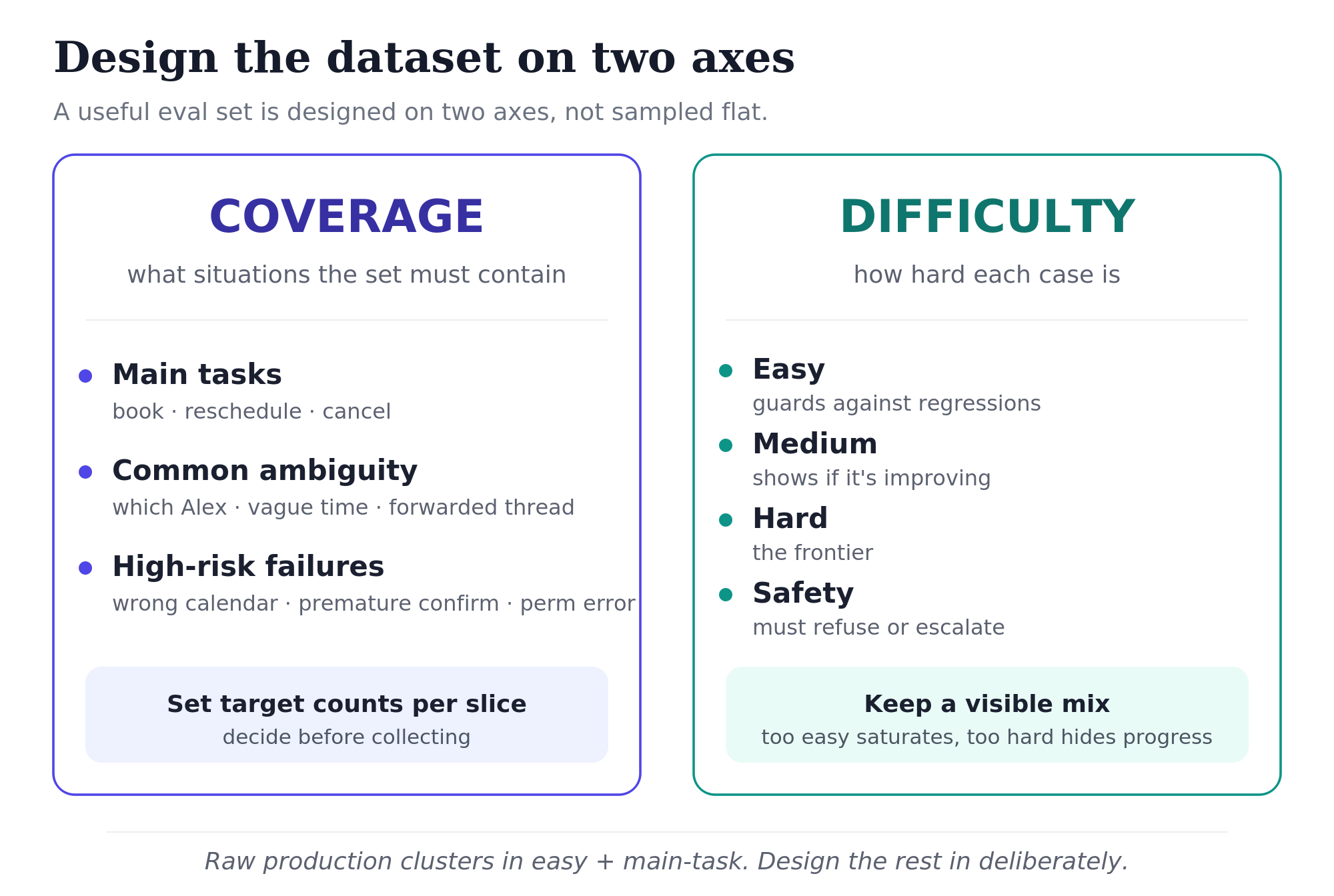
A raw production sample usually overrepresents easy traffic. For a scheduling assistant, that means lots of simple booking requests and too few high-risk cases: ambiguous attendees, wrong-calendar writes, permission errors, forwarded email threads, time-zone mistakes.
Design the dataset intentionally:
- Main tasks: booking, rescheduling, cancellation.
- Common ambiguity: unclear attendee, unclear event, vague time phrase, forwarded email thread.
- High-risk failures: wrong calendar, premature confirmation, missing conflict check, permission error.
Set target counts for the slices that matter most (30 ambiguous-attendee cases, 25 wrong-calendar cases). The numbers are illustrative; the point is deciding the targets before collecting.
For rare but important slices, do a cheap pre-filtering pass before full labeling. If wrong-calendar writes or permission errors are rare in raw traffic, find the candidate traces first, then label those carefully. In a clinical-note project I led, sections like allergies and labs appeared sparsely across clinician-patient transcripts; a quick yes/no pass identified which transcripts contained them.
Balance difficulty too:
- Easy cases: the system should already pass these. They protect against regressions.
- Medium cases: the system is mixed. These show whether the product is improving.
- Hard cases: the system often fails. These show the frontier.
- Safety cases: the system must refuse, escalate, or avoid forbidden behavior.
A dataset that is too easy saturates, and one that is too hard fails to show progress, so aim for a visible mix that tells the team what actually improved.
Eval scores are samples, not truth returns to sample size and uncertainty. If a slice matters, include it deliberately and track it separately.
When you don’t have production data
Before launch, the dataset has to come from somewhere other than production. Generate the inputs and let the real system produce the responses, then label the resulting traces like any other trace.
Two sources work well in combination.
Persona-based generation. Define three to five user personas that match the product (for the scheduling assistant: a time-zone-confused product manager, an executive with overlapping calendars, an IC handling forwarded meeting threads). For each persona, generate eight to twelve plausible queries.
Expert elicitation. Sit with someone who has done this product’s work before: a customer success lead, a power user from a prior product, a domain expert. Ask: “What is the worst question someone could ask this?” and “Where do you expect this to fail?” The answers encode failure intuition the team doesn’t yet have from data, including the high-risk cases the coverage section calls out.
The dataset is the product’s memory
An eval dataset is the product’s memory of what has gone wrong, what the team decided “good” means, and what must not break again.
That memory has to keep growing. The first version will be incomplete; failure modes will get sharper as production reveals new ones; the adjudicator will tighten the examples annotation guide as the team’s standard becomes clearer. The danger is pretending the dataset doesn’t need to evolve.