Your LLM judge is a classifier
An LLM judge that predicts PASS or FAIL is a classifier. Like any classifier, it has to be tested against human labels before its scores mean anything.
This is the step teams often skip. They build a judge, spot-check a few outputs, decide the verdicts look reasonable, and start reporting a pass rate. The dashboard may say the judge passed 87% of traces, but that number is only useful if the judge itself is reliable.
This article is about how to validate an LLM judge.
The running example is a documentation Q&A agent. The agent retrieves passages from internal docs and answers questions about a data-retention policy. For example, trial-account data is kept for 90 days, standard-account data for 30 days, and enterprise accounts under legal hold must be escalated.
The judge’s job is to check whether the answer is faithful to the retrieved source. In plain English: did the answer say what the document actually supports? Or did it use the wrong policy, drop an important caveat, or make a claim the document does not justify?
That is not something a simple regex can reliably check. It requires reading the question, the retrieved source, and the answer together. So it is a reasonable job for an LLM judge. The question is whether that judge is any good.
Validate against human labels
Validating a judge means comparing its verdicts against human labels on examples the judge has not seen.
The process is simple:
- Start with traces that humans have labeled PASS or FAIL.
- Keep a held-out set that is not used in the judge prompt.
- Run the judge on that held-out set.
- Compare the judge’s verdicts with the human labels.
- Report the confusion matrix, precision, recall, and F1 for the class that matters.
The held-out set is the key. If an example appears in the judge’s few-shot prompt or was used to develop the judge, it cannot also be used to validate the judge. The judge has already seen it.
Accuracy hides what matters
Suppose the faithfulness judge is tested on 100 human-labeled traces: 80 PASS and 20 FAIL.
It agrees with human labels on 83 of 100 traces, so the headline looks good: 83% accuracy.
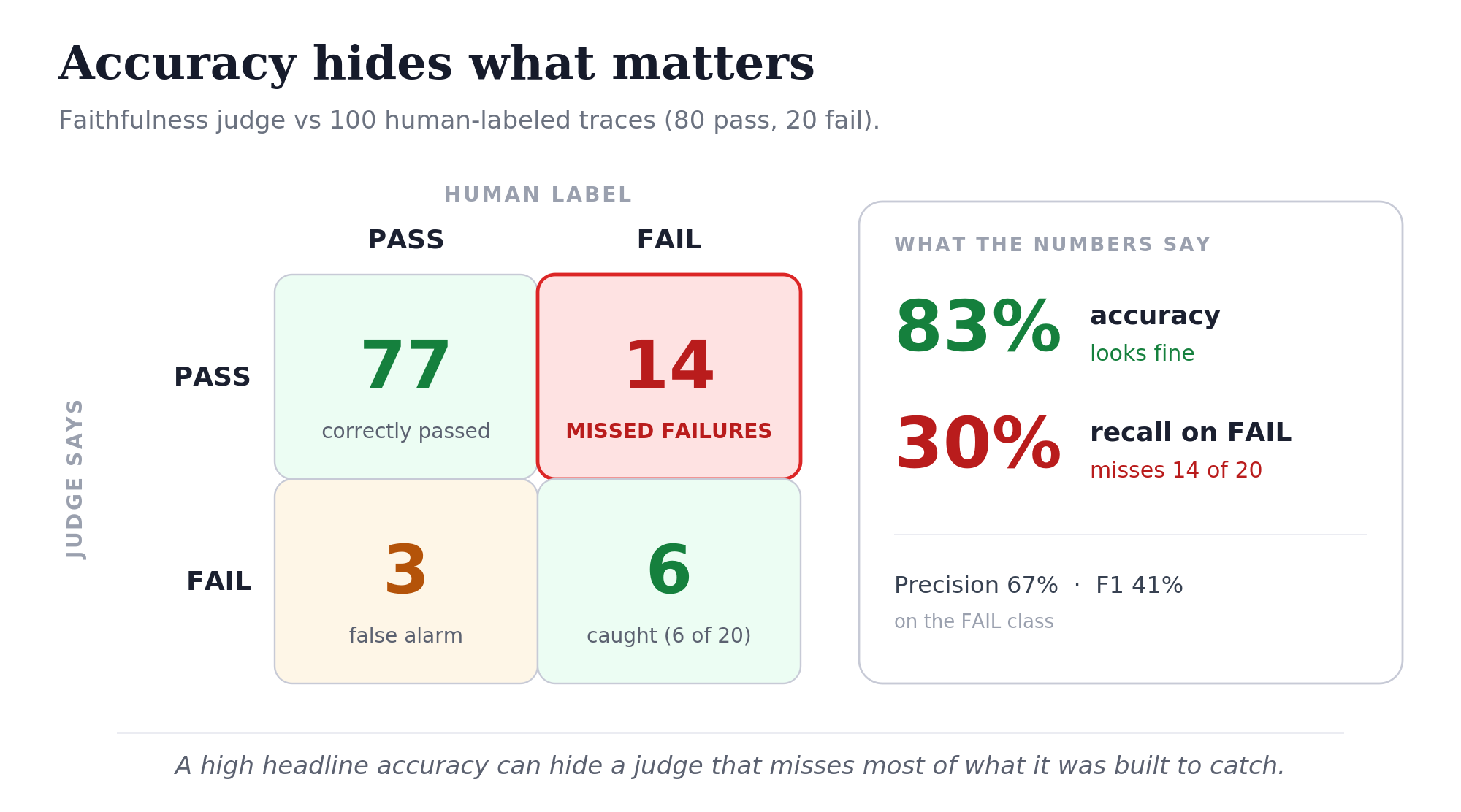
But the confusion matrix tells a different story:
| Human PASS | Human FAIL | |
|---|---|---|
| Judge PASS | 77 | 14 |
| Judge FAIL | 3 | 6 |
The judge correctly passes 77 of 80 faithful answers, but catches only 6 of 20 failures.
Accuracy = (77 + 6) / 100 = 83%
Precision (P) on FAIL = 6 / (6 + 3) = 67%
Recall (R) on FAIL = 6 / (6 + 14) = 30%
F1 on FAIL = (2 * P * R) / (P + R) = 41%So the judge is not good enough for faithfulness evaluation. It misses most of the unfaithful answers.
Hold out a real test set
Do not validate a judge on examples that appear in its prompt or were used to tune it. Split your labeled traces into: few-shot examples that go inside the judge prompt, dev set for iterating on the judge, and held-out test set for final validation only.
On the dev set, the most useful step is reading disagreements. For example:
- User question: “How long do trial-account records stay available?”
- Retrieved context: standard accounts keep records for 30 days; trial accounts keep them for 90 days.
- Agent answer: “Records are retained for 30 days after closure.”
- Judge verdict: PASS (found a matching sentence in the context).
- Human label: FAIL (the answer used the wrong account type).
That disagreement tells you what example to add: faithfulness requires support for the specific entity and condition in the user’s question, not just any matching sentence in the retrieved documents.
Once the judge performs well on dev, run it once on the held-out test set and report the result.
When calibration is poor
Reading the disagreements usually reveals one of a few patterns:
- Missing failure subtype. The judge catches outright hallucinations but misses subtle contradictions, dropped caveats, or unsupported generalizations.
- Over-flagging. The judge calls everything FAIL when the agent paraphrases instead of quoting verbatim.
- Unclear judging standard. The judge says some answers are unfaithful that the humans accept as fine.
- Right for the wrong reason. The verdict is correct but the critique points at the wrong thing.
- Too-small validation set. Wide error bars on metrics; unreliable conclusions (Eval scores are samples, not truth covers when this matters).
The fix progression is examples → criterion → model.
Examples almost always move first: if the judge is wrong on five cases of subtle contradiction, consider adding five contradiction examples to the few-shot block. If multiple disagreements trace to ambiguity in what counts as a failure rather than missing examples, the adjudicator sharpens the criterion. Model swaps come last. Most calibration problems live in the prompt, not the model, and switching models is expensive in cost, latency, and stability.
Revalidate when things change
The judge agrees with humans on the held-out set today. That doesn’t mean it will agree in six months. Foundation models update, the agent’s failure distribution shifts, and new failure types appear. Calibration is a snapshot that is accurate when measured and grows stale afterward.
Your eval system also drifts covers what to do about it: re-validate against fresh labels on a schedule and monitor agreement rates over time. Large drift in those agreement rates is usually a signal that the failure distribution itself has changed.
Every deployed judge should carry a short record of what it was validated on: the domain, the trace types, the test-set size, the date, and what it’s allowed to be used for. Without that record, judges get re-used on data the original validation doesn’t cover, and the team trusts a number that no longer applies.
The judge is part of the system
An LLM judge is a model component that needs the same discipline as any other classifier: held-out labels, a confusion matrix, precision and recall on the class that matters, and periodic revalidation.
Once the judge is validated, there is still one more question: how much should we trust movement in the score? A judge may report that v2 improved by two points, but that movement may be real or may be noise. The next article covers that next layer: uncertainty, sample size, and when an eval result is large enough to act on.