Information extraction didn’t disappear. It moved inside the workflow.
For thirty years, information extraction was a real subfield of NLP. Named entity recognition, relation extraction, event extraction, coreference resolution, slot filling, knowledge-base population. Annotated corpora: ACE, OntoNotes, KBP, TAC. A shared-task culture at every major conference. An entire industry of vendors and government-funded R&D organizations whose product was, essentially, structured records pulled out of unstructured text.
By 2024, the center of gravity had shifted.
The standard story is that LLMs replaced IE. What actually happened is that IE moved inside the workflow. Where the pre-LLM IE pipeline was the product (extract entities, link them, populate a knowledge base, ship the KB), modern IE is the structured layer between raw text and downstream generation or action.
The work still exists. What changed is the labor model. Pre-LLM IE required labeling thousands of examples per task, engineering features, training task-specific classifiers, and tuning a pipeline. LLM-era IE requires designing a JSON schema, writing a prompt, and evaluating the result. Both require real engineering of different kinds.
I worked across all three eras the article traces: pre-BERT IE during a postdoc, BERT-era production IE through the late 2010s, and LLM-era workflow IE now.
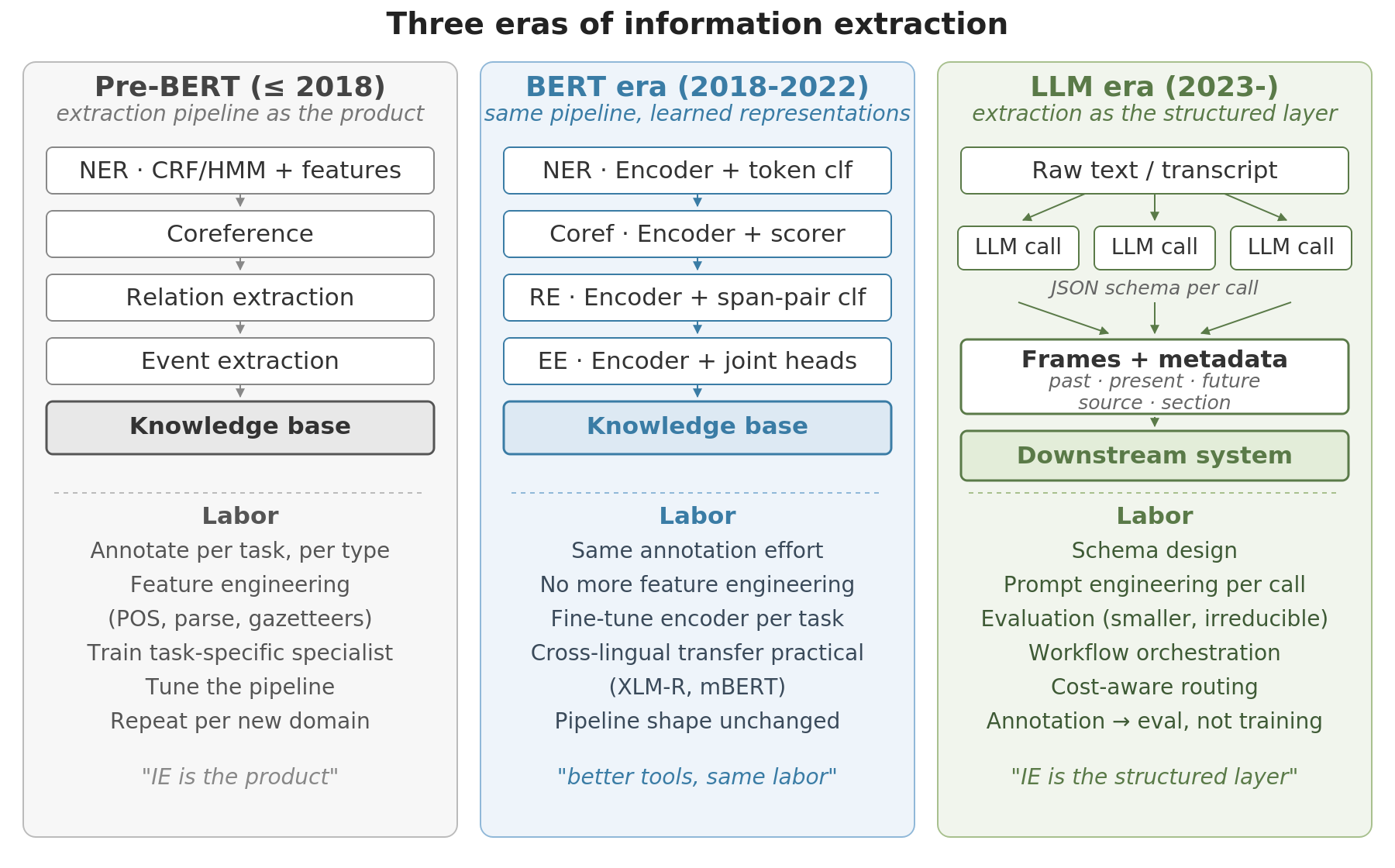
What IE used to look like
The canonical IE pipeline went something like this:
- NER: tag spans of text with entity types (PER, ORG, GPE, LOC).
- Coreference: cluster mentions that refer to the same entity.
- Relation extraction: for each pair of entities, classify the relation between them, if any.
- Event extraction: identify event triggers, classify the event type, then identify the arguments playing each role.
- Knowledge-base population: combine the above into a structured record per entity, linked across documents.
Each of these was its own subfield. Each had its own datasets: CoNLL-2003 (Tjong Kim Sang and Meulder 2003) for NER, ACE-2005 (Walker et al. 2006) for events and relations, OntoNotes (Hovy et al. 2006) for coreference, the TAC KBP datasets (Ji and Grishman 2011) for end-to-end knowledge-base construction. Each had its own modeling tradition: HMMs and CRFs for sequence labeling, structured-prediction for relation classification, ILP-based joint inference for combining extractions.
The labor was substantial and concentrated on the input side. To build an NER system for a new entity type, you collected text, annotated mentions (typically thousands per type), engineered features (word identity, POS, gazetteer match, dependency context), and trained a classifier. Relation extraction added another annotation pass per relation type. Event extraction added another for triggers and another for each argument role.
I worked in this regime during my postdoc. The published work from that period is on relation extraction (Chan and Roth 2010, 2011) and minimally-supervised event causality (Do et al. 2011). The relation-extraction setup was typical for the era: a feature engineering pass over syntactic and semantic structures (constituency parses, dependency paths, semantic roles, Wikipedia categories as background knowledge), then a structured classifier.
The defining property of pre-BERT IE was the labor model, not any particular architecture. Every new task, every new domain, every new ontology required a fresh labeling effort, a fresh feature-engineering pass, and a fresh trained model. Performance was decent on benchmarks and worse in domain transfer. Adapting to a new domain typically meant starting over.
BERT made IE better, not cheaper
BERT (Devlin et al. 2019) changed the modeling but not the labor. The pipeline shape stayed identical to the pre-BERT pipeline; the component models got better:
- NER became encoder + token classifier with BIO tags (what Hugging Face exposes as
AutoModelForTokenClassification). - Relation extraction became encoder + span-pair classifier: encode the sentence, pull out the two entity span representations, pool them, run through an MLP head.
- Event extraction became encoder + token classifier for triggers, plus a span-pair-style classifier for arguments.
- Coreference became span scoring and clustering over contextualized representations.
The improvements were real. The transition from feature engineering to learned representations was, in retrospect, the largest single quality jump IE had seen in a decade.
But the labor model was unchanged. You still needed labeled data per task. You still needed an annotation effort per new domain. The encoder did the feature engineering for you, but the rest of the work (schema design, annotation, evaluation) was the same as before.
I spent most of the BERT era on this kind of production IE: event extraction (Chan et al. 2019), KBP-style end-to-end systems (DeYoung et al. 2017), domain-specific machine reading and few-shot event mention retrieval (Min et al. 2019, 2020). I designed and built the deep-learning IE platform these systems ran on, layered on the Hugging Face ecosystem and used across government-funded and industry projects.
One multilingual event extraction project captures how sophisticated BERT-era IE had become. The training data was English, the inference target was Arabic, and the ontology covered roughly forty event types with typed argument roles. The stack used XLM-R (Conneau et al. 2020), multi-stage fine-tuning, token classification, continued MLM pretraining on mixed English-Arabic text, and automated checkpoint selection. This was not “just put a classifier on BERT.”
A second project, rapid customization of event extraction for new ontologies (Chan et al. 2019), was already gesturing at the LLM-era interface. The setup: take a small set of event-type definitions and a handful of seed examples, produce a working extractor without a full annotation effort. We compressed the labeling step with bootstrapping; the modern version puts definitions and examples into a prompt instead. What changed is that the definitions-plus-examples now condition a frontier LLM directly rather than seeding a bootstrapping loop.
The point of dwelling on this isn’t nostalgia. Too many current writeups treat the BERT era as a stepping stone: “people used to fine-tune classifiers, then LLMs came along.” That undersells the engineering. The systems were good. They were just expensive to build per task, which is exactly the thing the next era changed.
LLMs changed the labor model
IE was already possible before LLMs. What they changed was the cost structure.
A frontier LLM with structured-output support can solve most NER, RE, and slot-filling tasks zero-shot or few-shot from a prompt and a JSON schema. Quality is task-dependent:
- On standard benchmarks like CoNLL-2003, a well-prompted frontier LLM lands within a few F1 points of fine-tuned baselines.
- On harder benchmarks like ACE 2005 event extraction, zero-shot LLMs still trail fine-tuned specialists by double-digit margins (Zhang et al. 2025).
The gap closes with a handful of in-context examples or light fine-tuning on synthetic data. But for most use cases the marginal value of building a specialized BERT-era IE pipeline collapsed, because the engineering cost of getting from “no extractor” to “working extractor” dropped by an order of magnitude even when the LLM isn’t strictly best on F1.
The mechanics are by now well-known. The prompt asks for structured output. The schema is enforced by the provider’s structured-output mode (OpenAI’s response_format), or by Pydantic schemas as a type-checked output contract. For NER, the schema is a list of typed entities. For RE, a list of (head, relation, tail) triples. For event extraction, a list of frames with event type and roles. The LLM call replaces the entire encoder-plus-classifier-head stack.
Three modern IE patterns
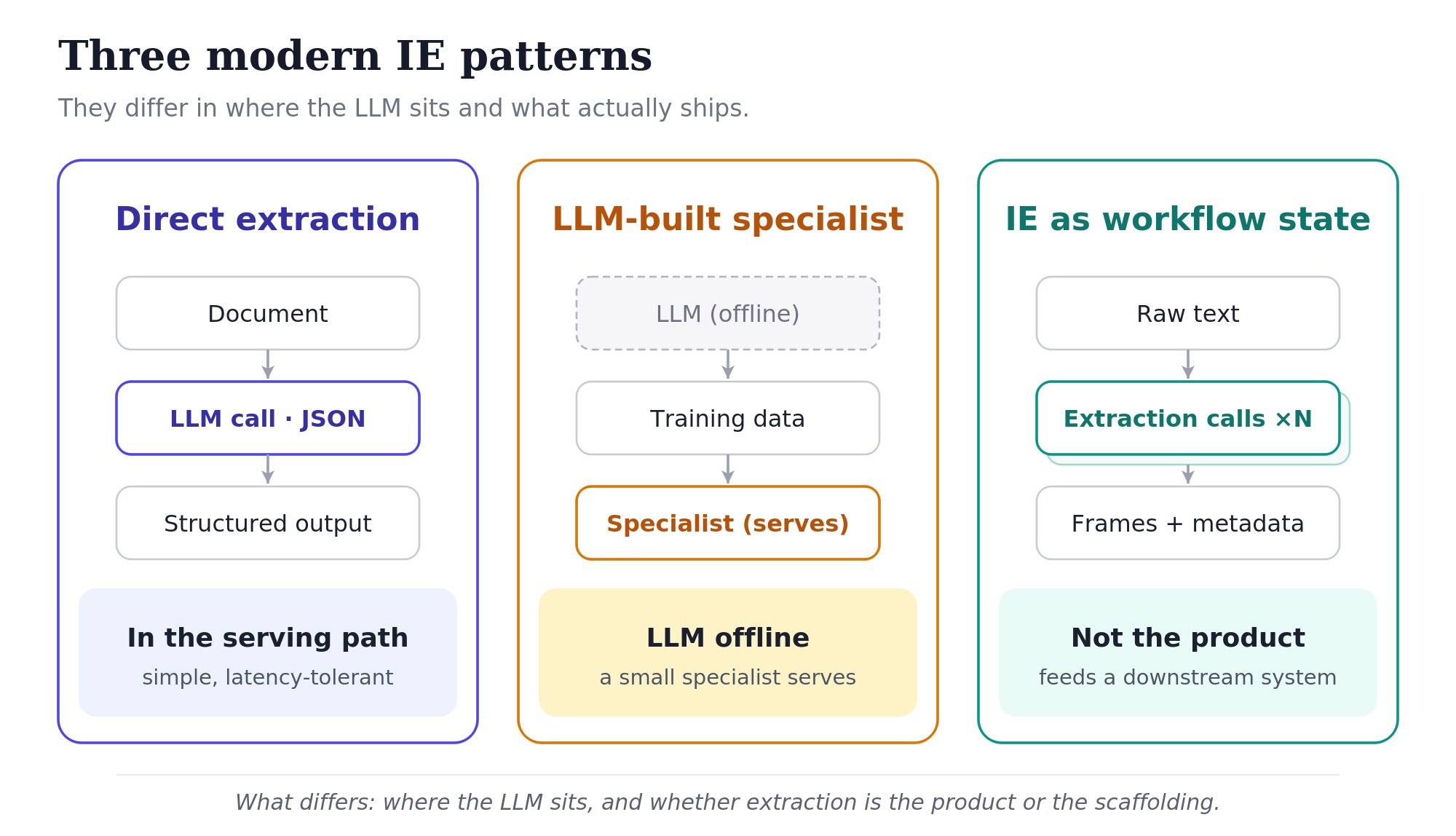
Direct LLM extraction
The baseline pattern: the production system makes an LLM call per document or chunk, parses the structured output, and uses it directly. It works for moderate-volume, latency-tolerant settings, and it’s the reference point the other two patterns are defined against.
LLM for data, specialist for serving
The hybrid pattern uses an LLM to generate training data, then trains a smaller specialist for production serving.
I ran into this in relation extraction over the MITRE STIX cyber security ontology (threat-actor, attack-pattern, malware, target, etc.). The available pre-LLM datasets were too sparse, incompletely annotated, or didn’t match STIX cleanly. The path forward: use GPT to extract candidate entities and relations from a few hundred documents. These LLM-generated annotations became training data for a DeBERTa-v3 (He et al. 2021) span-pair classifier (relations) and a T5 (Raffel et al. 2020) seq2seq tagger (NER, chosen because entity spans overlapped). The serving system never called GPT. It used the smaller specialists, trained on GPT-generated data.
The labor shift is the whole point. The classical version would have started with months of annotation. The LLM-era version started with prompt and schema design. The production model was still a classical encoder; the annotation cost collapsed.
IE as workflow state
The other interesting pattern is when extraction stops being the product. The product is a downstream system that uses extraction as its structured intermediate representation.
I’ve designed and led a clinical-documentation pipeline that takes a clinician-patient encounter transcript and produces a structured clinical note. The system uses multiple specialized LLM extraction calls: separate calls for problems and major note sections. Each extraction returns structured frames, with metadata attached so a downstream system can route facts into the right place:
- Example clinical note sections covered. History of Present Illness (HPI), Assessment & Plan (A&P), Labs / Test Results, Physical Exam, Allergies, Past Medical History.
- Frame fields, for a clinical problem. Symptoms, severity, duration, status, associated findings, treatments, medications, plan items.
- Metadata on each extracted item. Temporal status (past / present / future), source and stance (patient-reported vs clinician-assessed), section affinity.
- Downstream routing. Present-tense problem details go to HPI; clinician assessment and treatment plans go to A&P; past resolved history goes to medical history.
This is the modern form of IE I see most often: a structured control layer that lets the rest of the workflow behave reliably. The product is the clinical note; the extractions are what the downstream system builds it from.
The pattern isn’t unique. SpecialtyScribe (Goyal et al. 2025) and GENIE (Ying et al. 2025) are published instances of the same idea: IE as the structured intermediate layer of a workflow, with the extraction done by a frontier LLM, a fine-tuned smaller specialist, or a mix.
GraphRAG (Edge et al. 2024) is another version of the same move: use IE to turn documents into entities, relations, and summaries, then run retrieval and reasoning over that structure rather than over raw chunks. These are entity extraction, relation extraction, and light coreference, with the graph as the structured layer they feed.
The new labor: schema, prompts, eval, orchestration
The labor profile is different from BERT-era IE in specific ways. There is no large annotation effort for training. The center of the work is schema design, and the contrast is concrete. A weak schema for clinical problems is {"problems": ["chest pain"]}, a flat list of strings. A schema that lets the downstream system route, deduplicate, and surface evidence for clinician review looks more like:
{
"problem": "chest pain",
"status": "active | resolved | historical",
"temporality": "past | present | future_planned",
"source": "patient_reported | clinician_assessed",
"evidence_span": "...",
}The richer schema is what makes the workflow possible: every extracted fact carries the metadata the downstream system needs to act on it without re-extracting. Around that, the new labor is:
- Schema design: the frames, fields, metadata, and uncertainty behavior. The architecture decision that determines what the downstream system can do.
- Prompt design: per-extraction prompts that reliably fill the schema, iterated against failure cases.
- Evaluation: still labeled data, but at much smaller scale, for measuring rather than training.
- Workflow orchestration: how extractions compose, how frames are routed, where metadata gates decisions.
- Cost control: which calls run on a frontier model, which on a smaller specialist, which can be batched or cached.
None of this is less work than before. It moved from model training into workflow design.
When classical IE still wins
The “LLMs absorbed IE” framing oversells. There are concrete situations where classical IE wins.
High-volume or latency-sensitive serving. A DeBERTa-v3-base NER system runs at thousands of tokens per second per GPU at near-zero marginal cost; a frontier LLM call costs cents per document at a fraction of that throughput. If you process millions of documents per day, or a pipeline step has to run in tens of milliseconds, the encoder wins on cost and latency by an order of magnitude. The hybrid pattern (LLM-generated data, classical model serves) is the standard answer here.
Fine-grained span tasks under audit constraint. Medical coding, legal entity extraction, financial reporting: the span boundaries matter exactly, and LLM hallucination is unacceptable. A trained span-classifier with auditable failure modes is the safer choice. The LLM may generate the training data; the production extractor stays classical.
Ontology-backed coding and normalization. ICD-10 coding is not just extraction. It requires mapping clinical evidence to a controlled code system, following rules around specificity, exclusions and so on. A standalone LLM should not be trusted to do this from parametric memory alone. Use retrieval or lookup against the official code set and deterministic validation.
Stable schemas with mature labeled data. With a CoNLL-2003-scale labeled dataset and a stable schema, a fine-tuned encoder is hard to beat on the headline metric. The crossover varies by task and prompting strategy, but with thousands of labeled examples the encoder typically pulls ahead.
Code companion: TNLP IE examples
To make the transition concrete, my TNLP repo includes three working IE examples, written in late 2023 and early 2024, that map onto three stages of the shift.
Token classification / NER (BERT-era classical).
microsoft/deberta-v3-basewithAutoModelForTokenClassificationon CoNLL-2003, predicting the four canonical entity types. The standard “encoder + BIO tagger” pattern that became the default after BERT. Config, run script.Span-pair classification / relation extraction (BERT-era). A custom implementation, because span-pair classification has no clean off-the-shelf Hugging Face head when the code was written: encode the sentence with DeBERTa-v3, pool the two span representations, classify the relation. This is what production BERT-era RE actually looked like, a custom span aggregation on top of an encoder. Model, training.
Seq2seq NER with FLAN-T5 (the bridge to LLM-era). Instead of BIO tags, the model generates the sentence with bracket-tagged entity spans.
google/flan-t5-basewith LoRA (Hu et al. 2022) and 8-bit quantization. This handles overlapping and nested spans naturally (token classification can’t easily produce nested entities) and is structurally identical to how LLM-era extraction works: a generative model emits structured output. Code, config.
What people get wrong
Treating IE as deprecated. It isn’t. It’s everywhere: inside agents, RAG and knowledge graphs, structured data extraction, and so on. It’s just not explicitly labeled “IE”.
Skipping schema design. The schema is the architecture of the extraction layer. The single highest-leverage improvement to most LLM-extraction setups is tightening it.
Underweighting evaluation. Labeled data didn’t go away. It moved from training to eval. You can’t ship an IE workflow you haven’t measured, and measuring requires gold annotations. The eval set is the new annotation effort: smaller, but irreducible.
Picking the wrong model for the operating constraints. Try the LLM first for new or ambiguous tasks. Train a specialist when cost, latency, scale, auditability, or span precision force it. Both reflexes (always train a specialist; always reach for the frontier LLM) are mistakes. The constraints decide, not the fashion.
Treating extraction as the product. In modern systems extraction is rarely the product. It’s the structured intermediate layer between raw text and downstream generation, retrieval, or action.
Closing
For decades, information extraction was a product: annotate, train, extract, ship the knowledge base. BERT made the models better but left the labor model intact; every new domain still cost an annotation effort. LLMs did not make IE possible; it already was. They made it low-startup-cost enough that it stopped being a product and became infrastructure: the structured layer between raw text and whatever the system does next.
The extractor now serves as workflow state rather than the final deliverable.
The papers on the hard research problems (coreference, cross-document linking, strict argument-role constraints) are still being written; they’re just no longer where most production IE work happens. The next time someone says their system “doesn’t do information extraction,” it’s worth asking what the JSON between their LLM calls is.